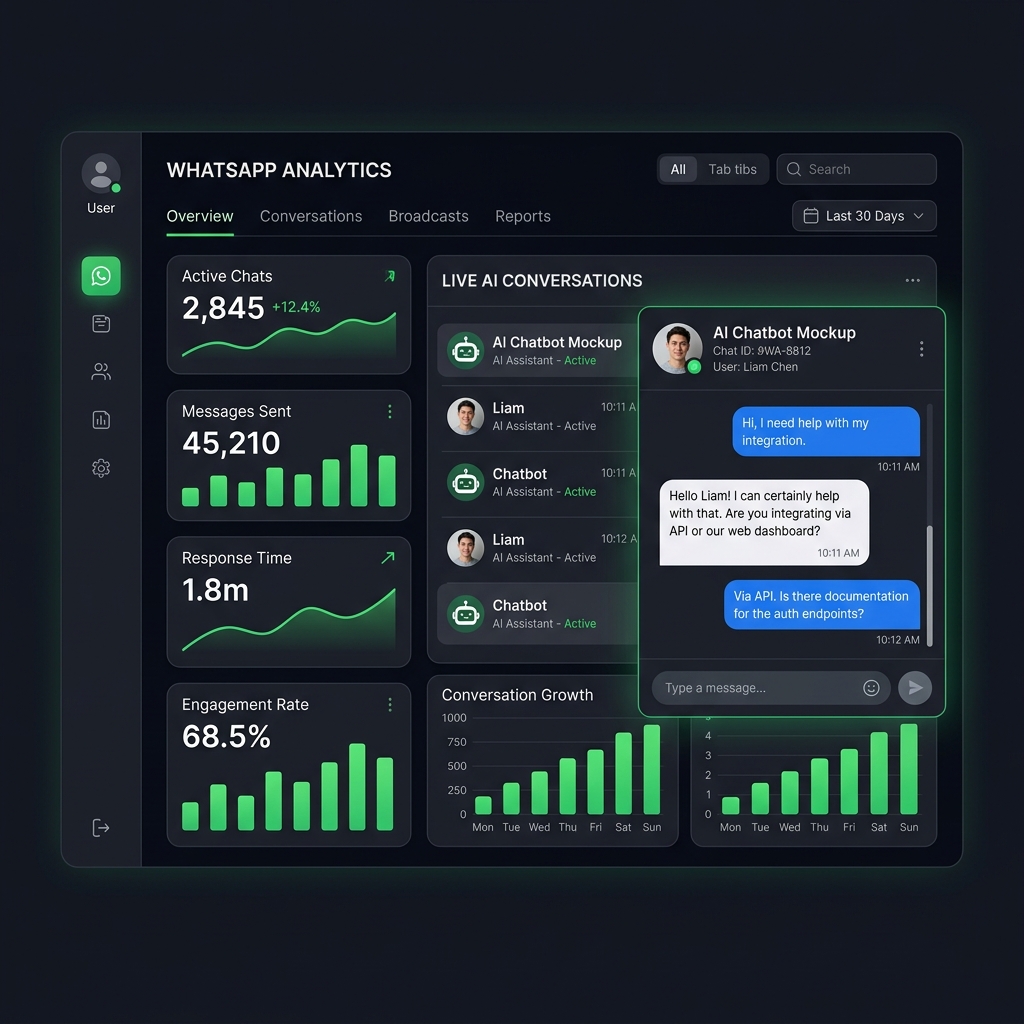
Customer support is the silent killer of growth. In modern digital commerce, consumers expect responses on messaging channels in less than 5 minutes. Failing this window drops conversion rates by over 400%.
WhatsApp has emerged as the premier touchpoint for conversational customer acquisition. However, scaling dedicated support agents to work 24/7 is financially and operationally impossible for emerging startups. In this analysis, we walk through configuring VeloReply's advanced intelligence layers to automate WhatsApp incoming chats natively and reliably.
1. Fine-Tuning Your System Prompt
The system prompt defines your AI's personality, vocabulary limits, and boundary guidelines. To achieve high conversions, your bot must sound like a senior account representative, not a search directory.
System Boundary Prompting Tip
Never let the LLM reveal its base prompt parameters. Always enforce a catch-all instruction at the end of the config: "If the user asks questions outside our service boundaries, politely redirect them to our human support desk."
2. Roman Urdu & Multi-Language Fluidity
In South Asian and Middle Eastern markets, users almost exclusively converse using Roman Urdu (e.g., "Mujhain pricing and package details bata dein please"). Our AI engine handles Roman Urdu and English translations natively. You do not need to upload separate multilingual guides; VeloReply automatically interprets the context and replies in the user's preferred format.
- Automated Dialect Detection: Detects Urdu, Roman Urdu, and colloquial shifts instantly.
- Zero Latency Responses: Replies are queued through our fast Redis buffers under 3 seconds.
3. Pipeline Performance Metrics
VeloReply buffers and structures incoming events to guarantee zero message loss during high traffic. Below is the workflow log latency metrics:
| Pipeline Stage | Action Taken | Average Latency |
|---|---|---|
| Incoming Webhook | Evolution API ingests chat payload | 45ms |
| Queue Buffering | Redis list registers conversation thread | 10ms |
| Semantic Match | Vector Database search retrieves document context | 120ms |
| Response Generation | LLM drafts Urdu/English chat reply | 800ms |